
PROBLEM CONTEXT: Transforming Citizen Engagement in Ghana through Large Language Models: Enhancing
Parliamentary Hansard Accessibility

The Problem
In any thriving democracy, access to timely, accurate, and clear information about governance is critical. Ghana’s Parliament, like many around the world, produces a wealth of information through its debates, legislative reviews, budget discussions, and oversight sessions. These deliberations are meticulously recorded in the Parliamentary Hansard, the official transcript of all parliamentary proceedings.
But there’s a challenge.
Much of this valuable record is still locked away in paper-based documents or stored in unstructured digital formats. While the Hansard is available on the Parliament of Ghana’s website, the format is often bulky and not optimized for quick search, analysis, or public interaction. Citizens, journalists, researchers, and even policymakers often have to sift through hundreds of pages to find a single relevant statement or debate.
This lack of accessibility has three major impacts:
- Barrier to Citizen Participation – When people can’t easily access or understand what happens in Parliament, it limits their ability to engage with and influence decision-making.
- Reduced Transparency and Accountability – Inaccessible records make it harder for watchdogs, media, and civil society to monitor government actions.
- Missed Opportunities for Data-Driven Insights – The Hansard contains rich qualitative data that could reveal trends, highlight key policy priorities, and help measure the impact of legislative work, but only if processed in a way that enables analysis.
For decades, the Ghana Statistical Service has excelled at collecting and analyzing quantitative data: numbers, figures, and statistics. However, qualitative data like the Hansard requires a different approach: one that can understand context, interpret language, and make meaning from unstructured text. This is where artificial intelligence, particularly Large Language Models (LLMs), offers game-changing potential.
Defining the Problem
Ghana’s 8th Parliamentary Hansards today exist largely as very long, static PDF documents often spanning hundreds or even thousands of pages per session, that are rich in official content, including detailed transcripts of debates, statements, bills, budget appropriations, and executive oversight discussions, but remain fundamentally unstructured, hard to navigate, and entirely non-interactive. This outdated format, rooted in traditional paper-based archiving, forces users to manually sift through dense text without the aid of modern tools like keyword searches, hyperlinks, or summaries, which severely limits searchability, reuse for research or policy analysis, accessibility for diverse audiences including those with disabilities or limited technical resources, and overall civic participation by hindering citizens’ ability to engage meaningfully with legislative processes, track policy evolution, or hold representatives accountable in a timely and informed manner.
What “static PDFs” actually mean here


- Monolithic, page-oriented files. The Hansard is organized as a continuous PDF with page/column markers, long transcripts, and many sections (statements, bills, committee reports, estimates, etc.). That layout is ideal for printing but poor for programmatic access. Users must manually read through hundreds of pages to find a single speech or decision.
- Minimal machine-readable structure or metadata. The official brief explicitly calls out the need to convert paper-based or scanned text into electronic, structured formats (via OCR and tagging). That implies the current files lack the metadata (speaker, date, debate topic, bill IDs, timestamps) needed for advanced search and analysis.
- Formatting that confuses automated tools. Hansards use multi-column layouts, footers, headers, page numbers and sometimes inconsistent speaker labels elements that break naive OCR and NLP pipelines. The sample Hansard demonstrates column markers and long multi-topic sections that require semantic segmentation before they’re usable
Approaching the Challenge.
Our Methodology
Our team is tackling this problem by designing and developing a comprehensive, user-interactive web platform powered by artificial intelligence (AI) and optical character recognition (OCR) technologies. This platform aims to bridge the gap between raw parliamentary records, primarily available as lengthy, static PDF documents, and actionable insights. By focusing on Ghana’s 8th Parliamentary Hansards, which are rich in transcripts of debates, motions, votes, and reports but trapped in unstructured PDFs, we will transform these into a dynamic, searchable resource. This will empower citizens, researchers, policymakers, and parliamentarians to engage more effectively with legislative processes.
The methodology revolves around a robust pipeline that starts with OCR for extracting data from PDFs, transitions to AI for processing, structuring, and model training, and culminates in a web-based interface for interactive access. We’ll leverage the provided Hansard resources, such as those from https://www.parliament.gh/docs?type=HS.
Here’s a detailed breakdown of the concept, emphasizing how OCR and AI will power the platform through data extraction, model training, and real-time functionality:
- OCR-Powered Digitization and Data Extraction from PDFs:
The Hansards, often spanning dozens or hundreds of pages i.e 38 pages, with content like Votes and Proceedings, Motions, and Tables on fund distributions exist as scanned or digital PDFs that are not inherently searchable. OCR technology will be the first line of processing to convert these into usable digital text. We’ll use advanced OCR libraries like Tesseract (open-source) or cloud-based services such as Google Cloud Vision or AWS Textract, integrated into our backend pipeline.- PDF Handling and Preprocessing: Begin by parsing the PDF structure; identifying pages, removing artifacts like page numbers, headers.
- Text Extraction and Segmentation: OCR will extract raw text, segmenting it into logical units such as speaker names (e.g., “Mr Second Deputy Speaker”), debate content (e.g., corrections to Votes and Proceedings), timestamps (e.g., “2.07 p.m.”), and structured elements like tables (e.g., extracting rows from Table 4 on sources of funds). For instance, in the sample, OCR would pull out debates on GETFund formulas, including amounts like GH₵10,385,604,000.00, while preserving context. We’ll handle challenges like multi-column text or interruptions (e.g., “[Laughter]”) by using zoning techniques to define regions in the PDF.
- Error Correction and Validation: OCR outputs can have errors (e.g., misread characters in faded scans), so we’ll apply rule-based post-processing and initial AI validation to clean the data. This results in a raw dataset of extracted text, ready for AI enrichment. By automating extraction, we can process large volumes of Hansard PDFs efficiently, creating a foundational corpus for training and powering the AI models.
- AI-Driven Data Structuring, Enrichment, and Model Training:
With the extracted text in hand, AI, particularly large language models (LLMs) like fine-tuned versions of Grok, GPT, or open-source models such as Llama, will take over to structure the data, derive insights, and train custom models tailored to parliamentary context. This step “powers” the platform by turning unstructured extracts into intelligent, queryable knowledge.- Structuring with Natural Language Processing (NLP): Using NLP techniques (e.g., via libraries like spaCy or Hugging Face Transformers), AI will organize the data into a structured format, such as a database schema. This means tagging entities: speakers (e.g., “Mr Mahama Ayariga” as Majority Leader), topics (e.g., “GETFund Allocation” via topic modeling), dates/timestamps, motions (e.g., “Suspension of Order 104(1)”), and cross-references (e.g., linking to Acts like GETFund Act 581). We’ll create JSON objects or a vector database (e.g., Pinecone or FAISS) for efficient storage, enabling semantic search.
- Enrichment and Insight Generation: AI will enhance the data by generating summaries (e.g., condensing a debate on DACF formulas), sentiment analysis (e.g., detecting agreement or criticism in speeches like “I beg to second the Motion”), and entity linking (e.g., connecting mentions of “Free Senior High School” across documents). For tables in the PDFs, AI will parse extracted tabular data into analyzable formats, allowing visualizations like charts on fund disbursements (e.g., Tertiary: GH₵957,533,000).
- Training Custom Models: To make the platform truly powerful, we’ll use the extracted Hansard data as a training corpus. Starting with a base LLM, we’ll fine-tune it on this domain-specific dataset (e.g., thousands of pages from the 8th Parliament) using techniques like supervised fine-tuning or reinforcement learning from human feedback (RLHF). Training will focus on tasks like: question-answering (e.g., “What was said about TVET funding?”), summarization, and prediction (e.g., modeling trends in education allocations over sessions). We’ll incorporate Ghanaian parliamentary context: procedural terms, local languages if present, and historical references, to improve accuracy. Data augmentation (e.g., generating synthetic queries) will ensure robustness, and we’ll validate models against held-out Hansard excerpts to achieve high precision (targeting 90%+ accuracy). This trained AI will “power” real-time features, making the platform responsive to user inputs.
- Ethical and Quality Considerations: During training, we’ll mitigate biases (e.g., ensuring balanced representation of political views) and maintain data privacy, complying with Ghanaian data protection laws. Iterative training on new Hansards will keep models up-to-date.
- User-Interactive Web Platform Integration:
The extracted and AI-processed data will fuel a responsive web app (built with React.js for the frontend and Flask/Django for the backend), where users interact intuitively.- Natural Language Interface: Powered by the trained LLM, users can query in plain English or local languages (e.g., “Summarize the GETFund debate on March 29, 2025”), with AI retrieving structured data from the database and generating responses, including excerpts, timelines, or visualizations (e.g., pie charts of sector disbursements from Table 1).
- Advanced Features: OCR-extracted tables enable interactive tools like filters (by date, speaker, topic) and exports. AI-driven recommendations suggest related debates (e.g., linking DACF motions to GETFund reports). For accessibility, include voice search (using AI speech-to-text) and summaries for visually impaired users.
- Scalability and Updates: The platform will support uploading new PDFs, triggering automated OCR extraction and AI retraining/fine-tuning in batches. This creates a self-sustaining system, reducing manual effort and promoting a paperless archive.
This methodology directly addresses the challenge’s goals: extracting, structuring, validating, training, and deploying, while overcoming barriers like PDF variability and contextual depth. By harnessing OCR for raw data liberation and AI for intelligent empowerment, “Hansard Hub” will democratize parliamentary data, fostering transparency and civic engagement in Ghana.
Design Concept
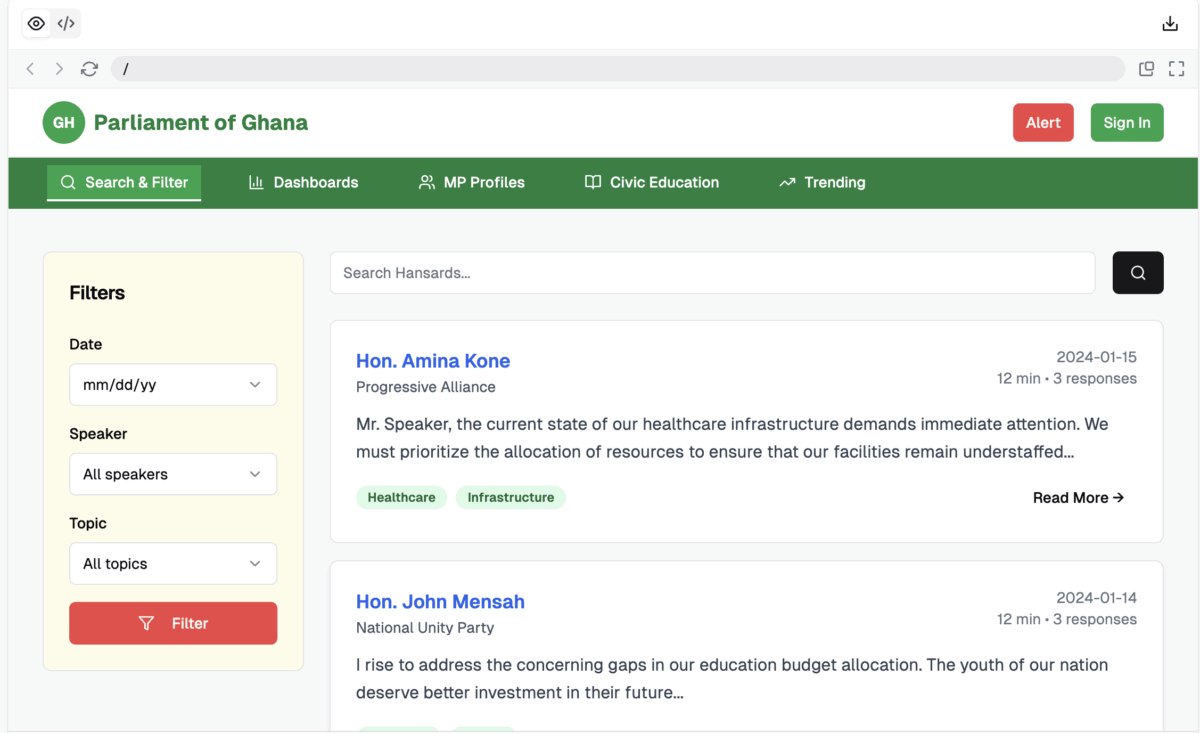
To bring our vision to life, we’ve conceptualized a modern, intuitive web platform that prioritizes user accessibility, interactivity, and seamless integration of AI-powered features. The design draws inspiration from contemporary government portals and search engines like Google and parliamentary websites (e.g., the UK Parliament’s Hansard search), while incorporating Ghana-specific elements such as the national colors (green, gold, red) and contextual references to local governance. The goal is to create a clean, responsive interface that feels familiar yet innovative, allowing users from everyday citizens to policymakers, to effortlessly navigate vast parliamentary records without technical barriers.
The Team
Our team consists of members with diverse and complementary skill sets. The Artificial Intelligence Engineer will focus on data extraction, cleaning, and model training. The Software Engineer, proficient in Angular, Spring Boot, and PostgreSQL, will be responsible for designing the database to store the data, developing a secure backend with well-documented RESTful APIs to communicate with the government parliamentary Hansard, and building an interactive frontend that integrates seamlessly with the backend. The Designer and User Experience Specialist will create a user interface that is intuitive, frictionless, and tailored to meet all project requirements.
TEAM LEAD
CHRISTOPHER MTOI

Experience in leadership, software development and AI.
Co founder of RAFIKI AI startup, leader of the students representative of the NMB Nuru Yangu, hands on experience on building scalable back end systems using springboot, PostgreSQL.
HAPPY WESTON

Proficiency in user experience and user interface design, with a focus on front-end development and creating practical, user-centered digital solutions. A confident individual in managing projects, communicating clearly, and working well with different teams
MUDDY FAKIH

Proficient in Java, Spring Boot, Quarkus, PostgreSQL, MySQL, and Docker. Hands-on experience with flutter and backend integration at District Health InformationSystem (DHIS2), Lono Gaming Hub, and clients projects as Consultant. Intermidiate-level skills in Angular for frontend development.
KHADIJA OMARY

Proficiency in front-end development using HTML, Tailwind CSS, and JavaScript, as well as network engineering, where I design and manage secure networks, blending design with strong technical systems.
GEOFREY ADOLF

Proficiency in marketing enthusiast with a strong foundation in strategic communication, digital branding, and customer engagement. My skill set includes content creation, social media strategy, market research, and data-driven campaign planning. I am particularly passionate about next generation digital innovations