
Empowering citizens through accessible parliamentary records for a more transparent democracy.

Bridging the Gap in Civic Participation
Re-imagining Civic Access: Transforming Ghana’s Parliamentary Hansard through AI
Elisha Soglo-Ahianyo, Kingsley Owusu Agyekum, Susanna Agyekum, Stephanie Davis, Narain Kobby Gaisie, Grace Aliko
Supervised By:
Prof. Ing. Alexander Boakye Marful
Dr. Oliver Kornyo
Top Level Keywords:
Parliamentary Hansard, Optical Character Recognition, AI Powered Solution, Machine Learning
Understanding The Problem
Parliament sits at the center of Ghana’s democracy: the place where laws are written, budgets are argued, and the public’s needs are negotiated. Yet too often the arc of those debates stops at the chamber doors. The official transcript, the Hansard, was created to connect citizens to their government’s deliberations, but in practice it is a library of records that few citizens can comfortably read, search, or use.
At first glance the obstacle looks simple: the Hansard is bulky. Hundreds of pages per sitting, thousands across a parliamentary term. But the problem runs deeper than volume. Much of the Hansard is trapped in scanned PDFs or archived print, formatted for legal and archival fidelity rather than comprehension. Even when the text is present, it is written in formal parliamentary English, dense with procedural terms, nested references, and cross-session citations. For an average Ghanaian student, farmer, trader, or teacher, the Hansard reads like a foreign language.
This is not just an inconvenience. The 1992 Constitution and the Right to Information Act (2019) enshrine a citizen’s right to information and participation in governance. Those rights are meaningful only when information is usable. If citizens cannot find “who said what about the 24-hour economy?” or “when the budget for free senior high schools was discussed,” participation and oversight remain aspirational rather than real.

Member of Parliament speaking
Defining the Problem:

Ghana’s 8th Parliamentary Hansard—our definitive record of debates, votes, committee work, and parliamentary decisions—sits at the intersection of law, policy and public life. Yet, in its current form it serves more as an archive for specialists than an instrument for public participation. The Hansard is often distributed as typed pages or long PDFs that are organized by sitting and session rather than by topic, speaker, or policy question. That format makes it slow to search, difficult to interpret, and effectively inaccessible for many citizens who need timely, verifiable information to participate in democratic life.
This is not only a technical problem; it’s a constitutional one. Article 21(1)(f) of the 1992 Constitution affirms that “all persons shall have the right to information” and Parliament enacted the Right to Information Act (Act 989) in 2019 to give practical effect to that right. For those legal guarantees to be meaningful, information must be usable—not only available. If citizens cannot quickly find “who said what about the education budget” or verify when a particular amendment was moved, the promise of oversight and participation remains hollow.
Approaching the Challenge
Our Methodology
In this initial phase of our work, we have adopted a methodical and context-driven approach. The first step has been to digitize the Hansard through Optical Character Recognition (OCR) tools such as Amazon Textract and Tesseract. These technologies allow us to extract text from scanned parliamentary documents and prepare them for analysis. Once extracted, the text is cleaned and structured into meaningful units. We segment the content into debates, questions, responses, committee reports, and procedural items, labeling each with metadata such as speaker names, political affiliations, dates, bill titles, and keywords.
Beyond digitization, our work also involves applying Natural Language Processing (NLP) tools to extract useful information. Using pre-trained models fine-tuned to parliamentary language, we are developing systems that can identify key entities—such as Members of Parliament, regions, ministries, and policy areas—and automatically generate plain-language summaries of each session. These summaries will provide users with a simplified overview of what was discussed, who contributed, and what decisions were made.
1) Dual-track, layout-aware OCR & canonical text
We begin by digitizing the Hansard through a hybrid text recognition process that reads both typed and scanned pages. This involves using intelligent tools that can detect complex layouts — including columns, headers, and speaker names — while ensuring that every extracted line reflects the original document. To control cost and improve coverage, we combine advanced services like Google Vision and Amazon Textract with lightweight open-source tools such as Tesseract. Each output is saved in two forms: the raw OCR text and a cleaned, human-readable version known as the canonical text. To maintain transparency, every piece of text is stored with reference details like page number, line range, and OCR confidence score, ensuring that users can always trace digital text back to the original scanned page.
2) Human-in-the-loop verification on high-value content
Because technology alone cannot guarantee full accuracy, we integrate human reviewers into the process. Editors and analysts manually review key sections — such as committee reports and budget debates — where precision matters most. Through a simple annotation interface, they correct speaker names, political affiliations, and any OCR errors. Every change is recorded with details of who made it and when, creating a visible audit trail. This combination of automation and human oversight produces a transparent, trustworthy, and continuously improving dataset.
3) Smart chunking, rich metadata, and canonical indexing
Once verified, the text is divided into logical segments or “chunks” based on who is speaking or what is being discussed. Each chunk is tagged with detailed metadata including the speaker’s name, party, committee, date, and session ID, along with page and confidence references. The system also identifies important entities such as ministries, bills, and numerical figures, which makes the content easier to organize and retrieve. This structured, metadata-rich indexing forms the backbone of an intelligent search engine that can later power meaningful queries.
4) Embeddings & retrieval design
To make the Hansard searchable, we convert each chunk into a mathematical representation called an “embedding.” This allows the system to recognize related meanings rather than just matching words. These embeddings are stored in a searchable database, so when someone types a question, the system can locate the most relevant parts of the Hansard. The retrieval process balances accuracy and efficiency — ensuring that searches like “What did Parliament say about agricultural funding in 2022?” return the right excerpts quickly and reliably.
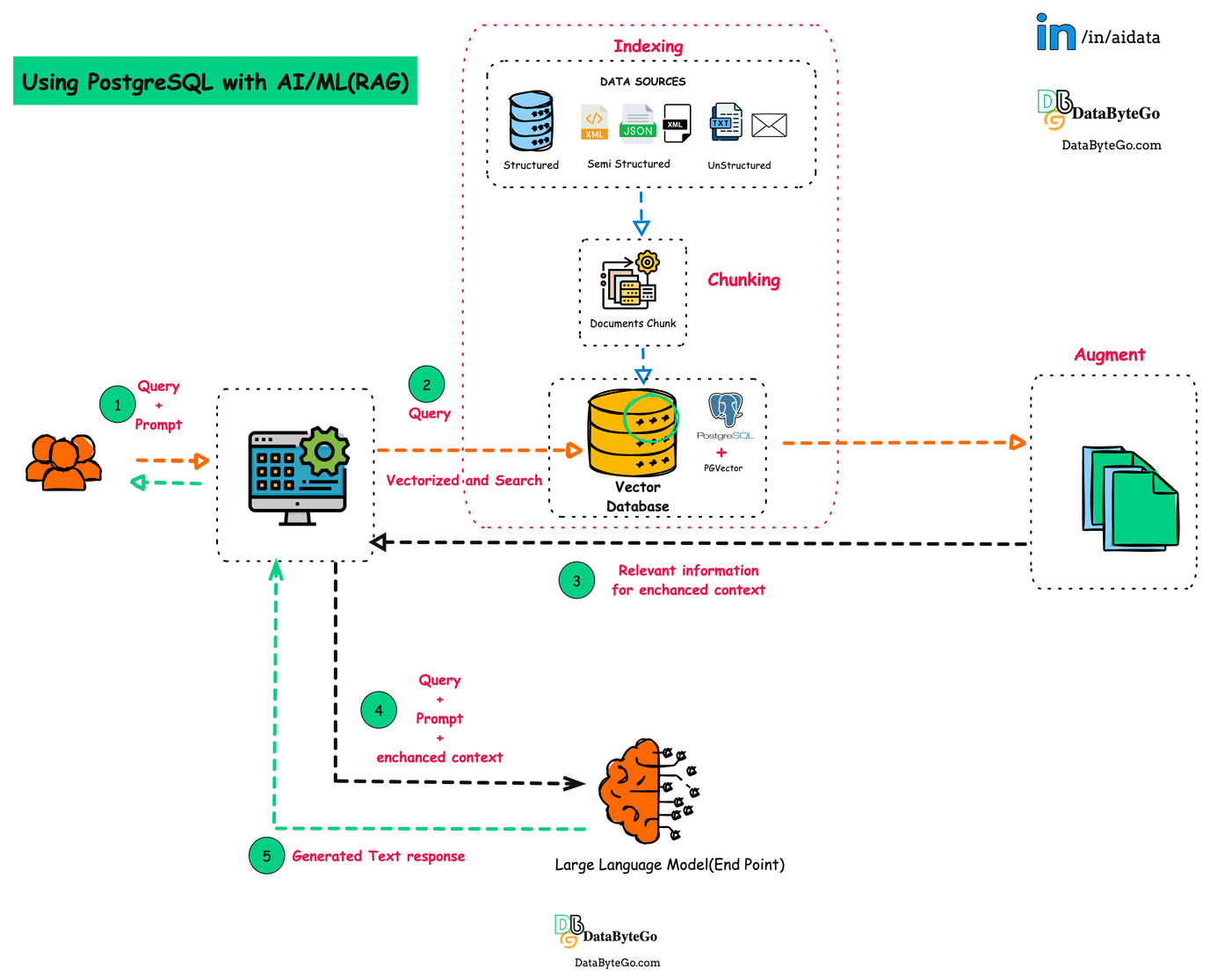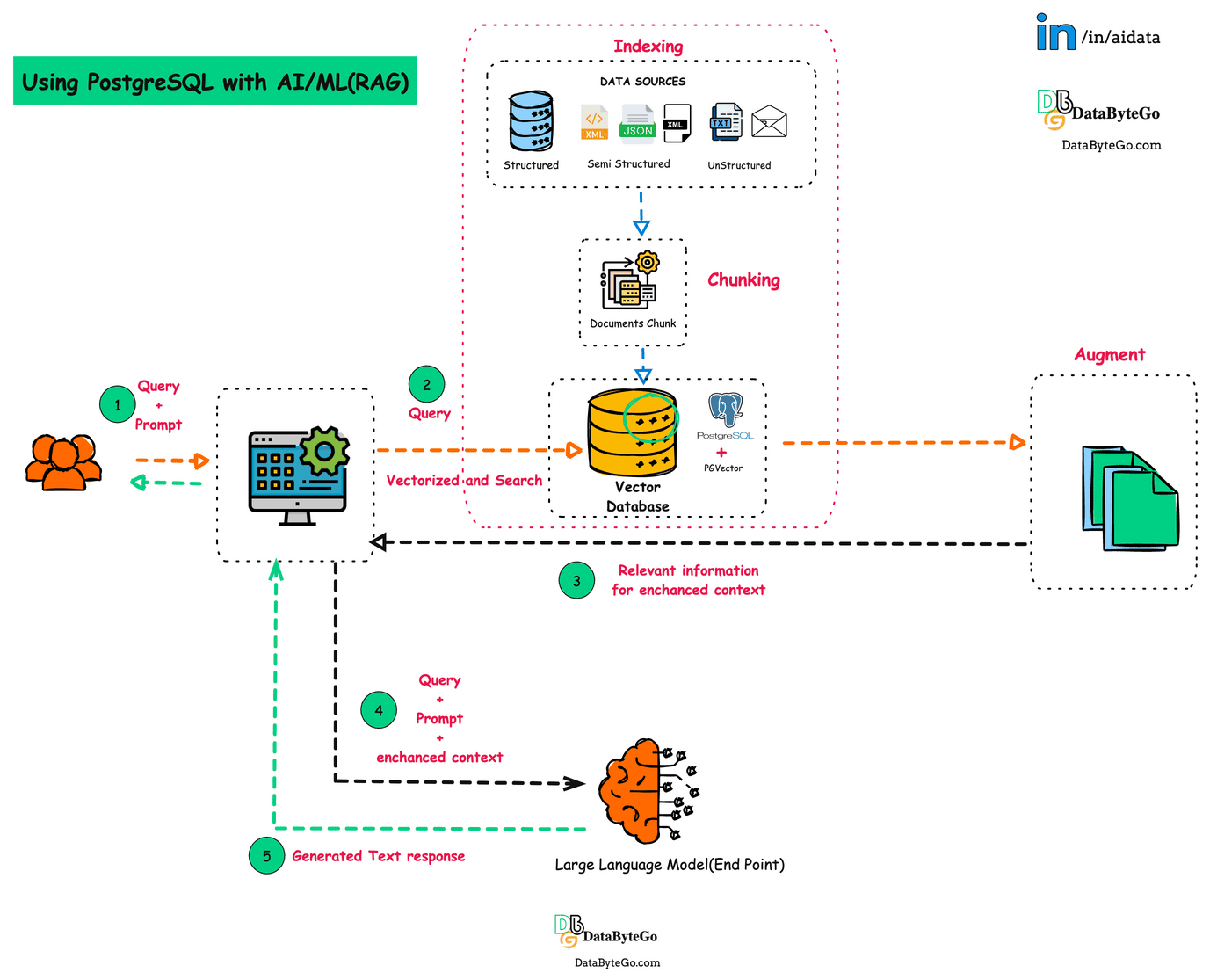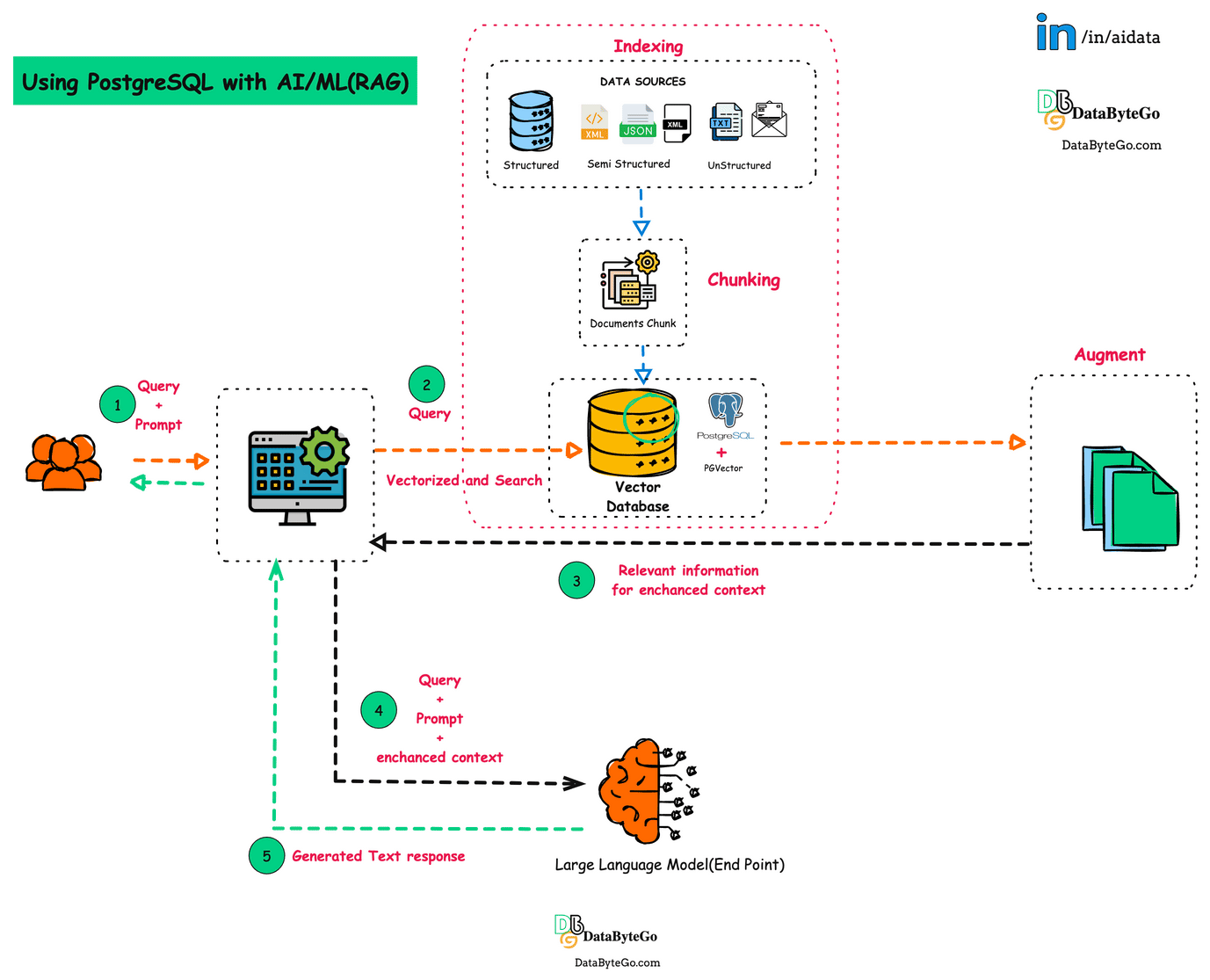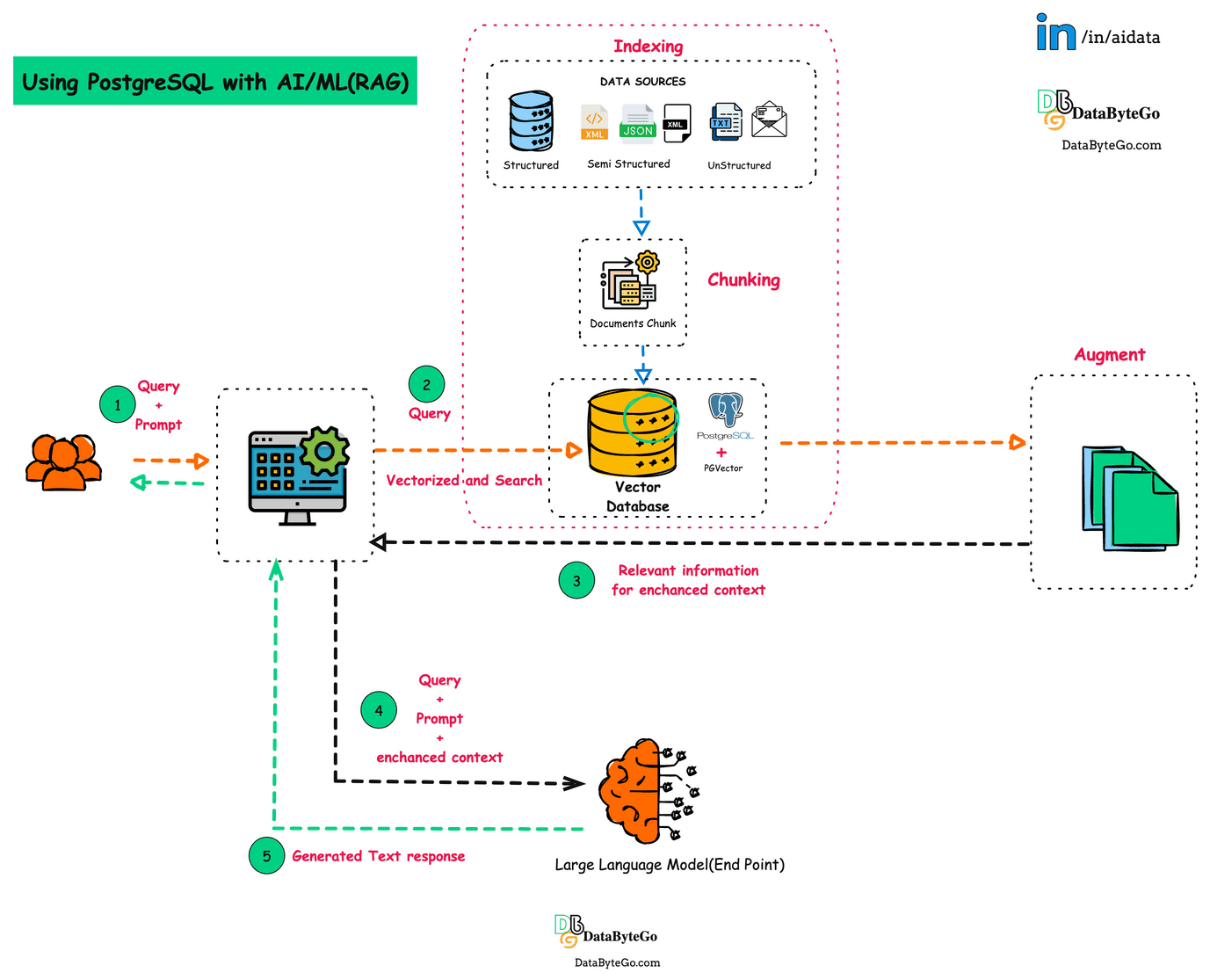
5) RAG (fast MVP) → RAFT (production hardening) roadmap
Our AI learning process follows two main stages. The first stage, called the Retrieval-Augmented Generation(RAG), builds a fast prototype that retrieves the most relevant Hansard sections and uses them to generate clear and referenced summaries. This phase helps us test how real users interact with the system. The second stage, called Retrieval-Augmented Fine-Tuning (RAFT), improves the AI’s reliability by training it with verified examples, so it learns to cite only from trusted content and avoid errors. Together, these stages ensure that the final model is both intelligent and dependable.
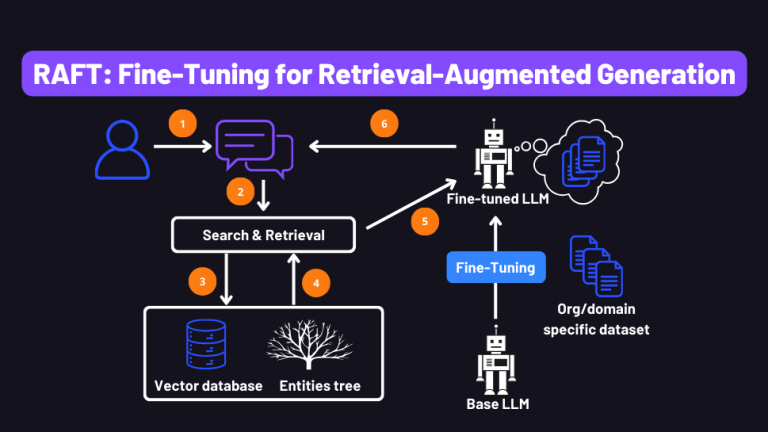
6) Model & fine-tuning strategy (practical economics)
We focus on using cost-effective but high-performing models that can run efficiently on limited hardware. Models like Microsoft’s PHI-3 or Mistral are adapted using lightweight fine-tuning methods that enhance performance without increasing expenses. When greater precision is needed, external language models like GPT-4 can be integrated for deeper summaries. This balance between open-source and hosted tools keeps our system flexible and sustainable.
7) Multimodal inclusivity: audio, IVR, SMS, and local languages
Accessibility is central to our approach. We recognize that not every Ghanaian reads English or owns a smartphone, so the platform provides multiple ways to access information. Each response can be viewed as a full excerpt, a short plain-language summary, or an audio version in languages such as Twi, Ewe, Ga, Dagbani, Hausa, and Fante. Citizens without internet access can call a phone number, ask a question in their language, and receive an audio response or a text message summary. This ensures that the Hansard truly belongs to all citizens — not just the digitally privileged.
8) Provenance, auditability & dispute handling
Every answer the platform generates includes a “source card” showing exactly where the information came from — the MP’s name, the date, the page number, and the level of text confidence. If users spot an error, they can flag it for review. These reports go into a moderation queue, where human reviewers confirm and correct the content. The updated and verified information is then fed back into the system, allowing it to continuously learn and improve. This loop of transparency builds public trust in both the technology and the institution it serves
9) Evaluation metrics & acceptance criteria
To measure the platform’s effectiveness, we monitor several key indicators. We aim for over 95% accuracy in text recognition, high retrieval precision when users search for specific topics, and strong agreement between AI-generated summaries and expert-written ones. We also test how easily different groups — from students to rural citizens — understand the responses. Beyond accuracy, we track system responsiveness to ensure that citizens can get answers in just a few seconds. These metrics help maintain accountability and guide ongoing improvement.
Challenges with the existing problem:
We identified two main formats the Hansard documents could have. Scanned PDFs are image-based documents that require OCR (Optical Character Recognition) to extract text. Typed PDFs are text-based and are directly readable by machines. To address both formats, we designed a dual-pipeline architecture.
Tackling the challenge
The challenge of making Ghana’s Hansard usable begins with the documents themselves, which exist in two primary formats: scanned PDFs and typed PDFs. For the scanned documents, we employ layout-aware OCR solutions such as Google Cloud Vision and Amazon Textract, complemented by Tesseract for fallback and cost efficiency. This dual approach allows us to not only convert images into machine-readable text but also to preserve critical features such as columns, headers, and speaker labels. Every OCR output is saved in two forms: the raw machine output and a cleaned “canonical” text, each tagged with metadata like the source PDF, page, line range, and OCR confidence levels. This design ensures that every generated claim can be traced back to the original page image. To build trust, we calculate word-error-rates on representative samples, targeting at least 95% accuracy on high-value pages like committee reports and budget debates. Where the OCR process is uncertain, a lightweight annotation interface enables human reviewers to correct speaker names, party labels, or key metadata, with every change logged for auditability and for training improved correction rules later.
For typed PDFs, the process is more straightforward, using libraries like PDFPlumber and LangChain loaders to extract text directly, though even here normalization is crucial since Hansards often contain repeated headers or formatting that can confuse later steps. Once extracted, both scanned and typed text are processed into coherent “chunks.” Whenever possible, these chunks are aligned to speaker turns so that each contribution can be retrieved in full. Where speaker attribution is unclear, the fallback is semantic chunking into passages of 200–800 tokens. Each chunk is richly tagged with metadata, including speaker, party, committee, session ID, date, and structured entities such as ministries, bill numbers, and numeric amounts. These details not only improve retrieval precision but also create the scaffolding for search filters like “all debates on the education budget in 2022” or “what Ablakwa said on university funding.”
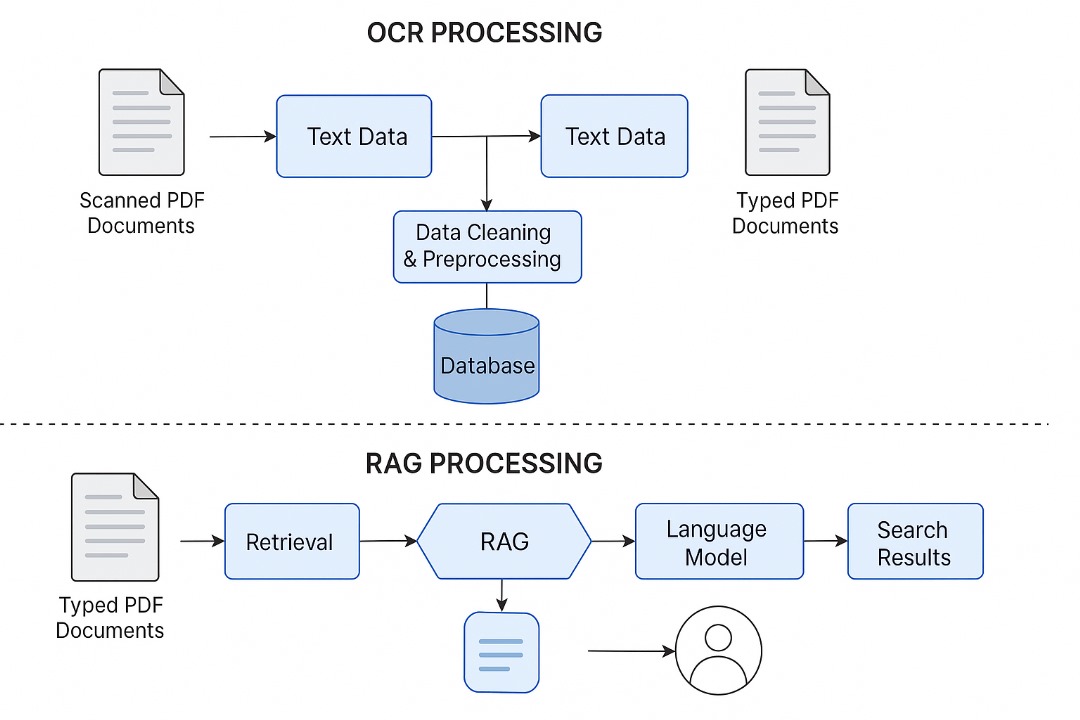
The cleaned and chunked text is then transformed into embeddings using cost-efficient but high-quality models such as MiniLM or Instructor-style sentence transformers. For small-scale pilots, the embeddings are indexed in FAISS or Chroma, while larger production deployments may use managed services like Pinecone or Weaviate. Retrieval combines top-k semantic search with a reranker, ensuring that the most relevant passages are returned first, even when users ask in natural, everyday language. This setup already supports powerful search, but the true intelligence emerges in the generation stage.
At this point we adopt a phased approach: Retrieval-Augmented Framework (RAF) for prototyping and Retrieval-Augmented Fine-Tuning (RAFT) for production hardening. With RAF, the system retrieves the most relevant Hansard chunks at query time and passes them, along with carefully structured prompts, into a large language model such as PHI-3 or GPT-3.5. The model is instructed to answer strictly from the retrieved text and to include explicit citations with MP name, date, page, and line numbers. This delivers immediate value: full excerpts, plain-language summaries, and longer explanations all grounded in verifiable sources. Once this foundation is proven and user feedback is collected, RAFT comes into play. By fine-tuning the model with curated examples of queries, retrieved passages, distractors, and correct answers, RAFT teaches the model to cite more faithfully, ignore irrelevant context, and consistently produce accurate, simplified summaries. This two-stage process allows for rapid iteration early on and robust reliability later, balancing speed with trust.
Accessibility is at the heart of this pipeline. Every answer is delivered in multiple modalities: a full text excerpt for journalists and researchers, a one-line or paragraph summary for moderately literate users, and an audio version generated through text-to-speech engines for citizens who prefer or require listening in Twi, Ewe, Ga, Dagbani, Hausa, or English. To reach those without smartphones, an IVR system allows a user to dial a number, ask a question in a local language, and hear an audio response or request an SMS with a summary link. Video content is also integrated, as YouTube transcripts are indexed into the same vector database, making it possible to surface relevant clips alongside textual answers.

Crucially, provenance is never an afterthought. Each generated output carries a “source card” that shows exactly where the claim comes from, including OCR confidence levels and links back to the original Hansard page. Where summaries synthesize multiple passages, the system shows which segments fed into each sentence. Citizens and journalists can flag inaccuracies, triggering human review and corrections that both update the live dataset and feed back into the RAFT fine-tuning corpus.
Design Concept:
The platform’s design centers on turning archived Hansard pages into trustworthy, multilingual, multi-modal civic outputs by combining robust extraction, precise semantic search, and a staged RAG/RAFT generation strategy: first we ingest documents from S3 using a layout-aware OCR pipeline (Google Cloud Vision / AWS Textract as the primary engines with Tesseract as a low-cost fallback) that preserves column structure, headers, and speaker labels; we keep both the raw OCR outputs and a cleaned canonical text with metadata (source PDF, page, line range, OCR confidence) so every downstream claim is traceable.
For typed PDFs we use PDFPlumber and LangChain loaders but still normalize repeated headers and footers before we chunk. Chunking favors speaker turns when available and otherwise produces semantically coherent passages (~200–800 tokens) annotated with rich metadata (speaker, party, date, committee, bill ids, numeric amounts) and extracted entities produced by hybrid NER (rules + fine-tuned Transformers such as spaCy/Hugging Face models). Each chunk is embedded (evaluate compact options such as all-MiniLM/Instructor-style models for cost-effective pilots and compare to higher-quality OpenAI embeddings where budget allows) and indexed into a vector store: FAISS or Chroma for private PoCs and Pinecone/Weaviate for managed, scalable production. Retrieval uses top-k semantic search with a lightweight reranker (cross-encoder or BM25 hybrid) so legal and parliamentary queries return precise passages; auxiliary corpora (YouTube transcripts, committee PDFs, budget datasets) are embedded alongside Hansard chunks so the same retrieval call can surface related videos or supporting documents.
Generation is staged: we start with a RAF (retrieval-augmented framework) MVP that concatenates retrieved chunks into citation-aware prompts and calls a chosen LLM to return a) the full quoted excerpt, b) a 1–2 sentence plain-language summary, and c) an expanded explanation with a “source card” (MP name, date, session, page, line range, OCR confidence and clickable PDF image). For production hardening we prepare RAFT (Retrieval-Augmented Fine-Tuning) datasets — query + oracle chunk(s) + distractors + gold answers — and fine-tune the model with PEFT methods (LoRA / QLoRA) so it learns to ignore distractors and reliably cite the correct passages, substantially reducing hallucination in domain Q&A. On model choice, PHI-3 (Microsoft’s Phi family) is a practical primary candidate for local/low-cost inference and multilingual deployments, with Mistral / LLaMA variants or hosted GPT (3.5/4) available for higher-quality or hybrid flows depending on budget and latency needs; use lightweight hosted calls for occasional high-quality summaries while running tuned open models for everyday traffic. Multimodal delivery is built in: every summary converts to TTS (evaluate Azure/Google TTS for Twi, Ewe, Ga, Dagbani, Hausa and fallback English), and an IVR/SMS layer (Twilio or local telco APIs) enables feature-phone users to call, ask a question in a local language, and hear or receive a short verified summary. Videos are surfaced by indexing YouTube transcripts in the same vector index and returning clip links with timestamps.
The frontend can be a responsive React + Tailwind app (or Streamlit for rapid demos) and the backend a stateless FastAPI service backed by PostgreSQL/Supabase for metadata and the vector DB; monitoring, logging, and an annotations UI support human-in-the-loop corrections that feed both provenance audit trails and the RAFT training corpus. To preserve trust, each generated answer shows provenance and a “flag” button that routes disputed items into a human review queue; corrected items are versioned and used as high-quality labels for subsequent RAFT fine-tuning. Operational KPIs include OCR WER targets, top-1/top-5 retrieval precision on a held-out query set, human agreement on summary fidelity, and median retrieval+generation latency under a production threshold; ethically, the stack must align with Ghana’s Right to Information practice by surfacing direct links for RTI requests and protecting user query logs with clear retention policies.
2) Human-in-the-loop verification on high-value content
In short, the design keeps your original toolset (Google Vision / Textract / Tesseract, PDFPlumber, spaCy/Hugging Face, MiniLM/SentenceTransformers, FAISS/Chroma/Pinecone, PHI-3, React/FastAPI) but embeds them into a traceable, inclusive pipeline (layout-aware OCR, speaker-aware chunking, semantic retrieval + reranking, RAF→RAFT progression, PEFT fine-tuning, multilingual TTS and IVR, provenance UI) so every Ghanaian—researcher, MP, journalist, student, or feature-phone user—can ask “What did X say about Y?” and receive a concise, verifiable, and usable answer.
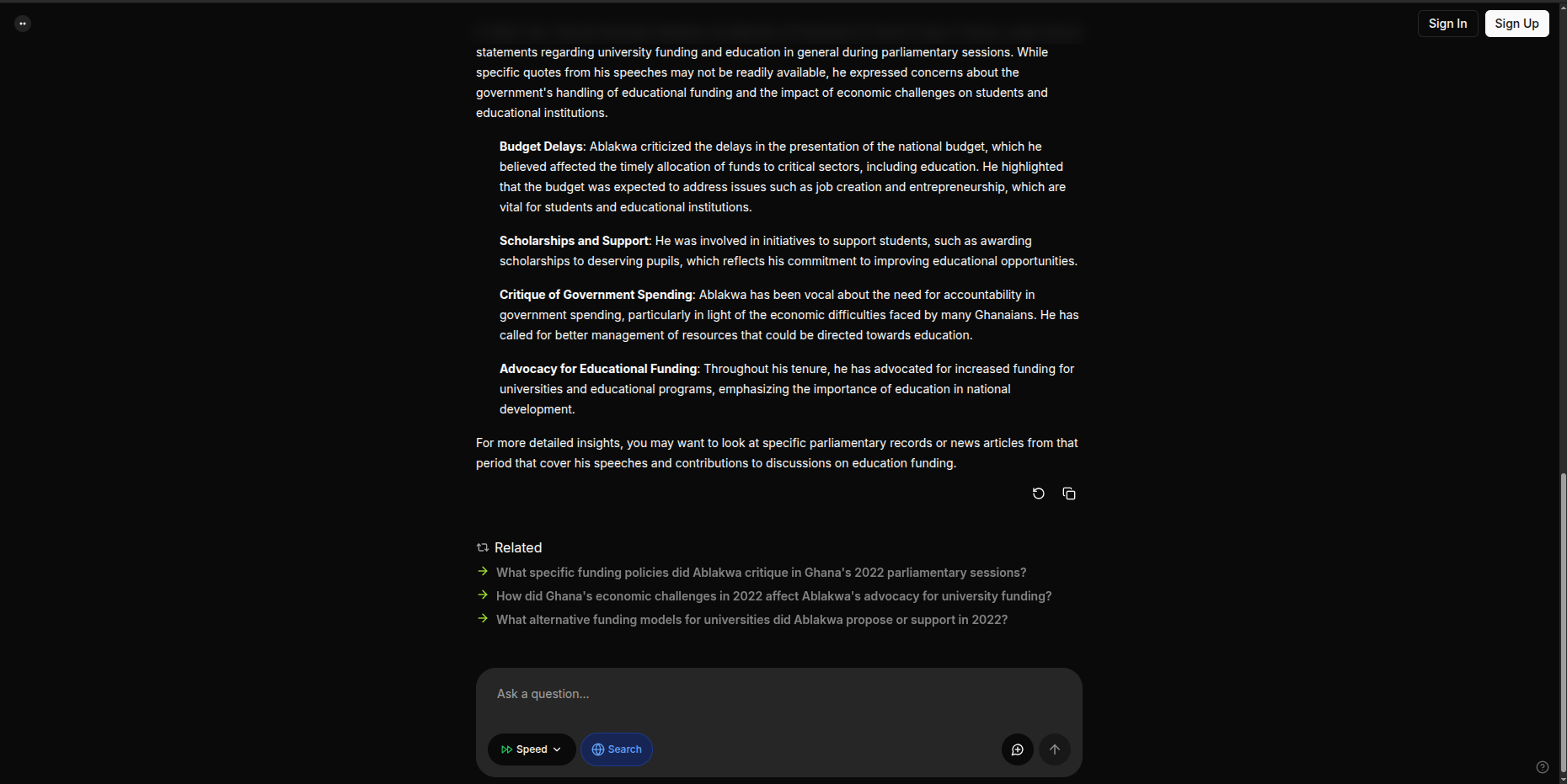
Imagine a citizen asking, “What did Hon. Samuel Okudzeto Ablakwa say about university funding in 2022?” Our system retrieves the right Hansard sections using semantic vector search. It sends those sections to Phi-3, which generates a concise, accurate summary. The answer appears instantly — readable, traceable, and shareable.
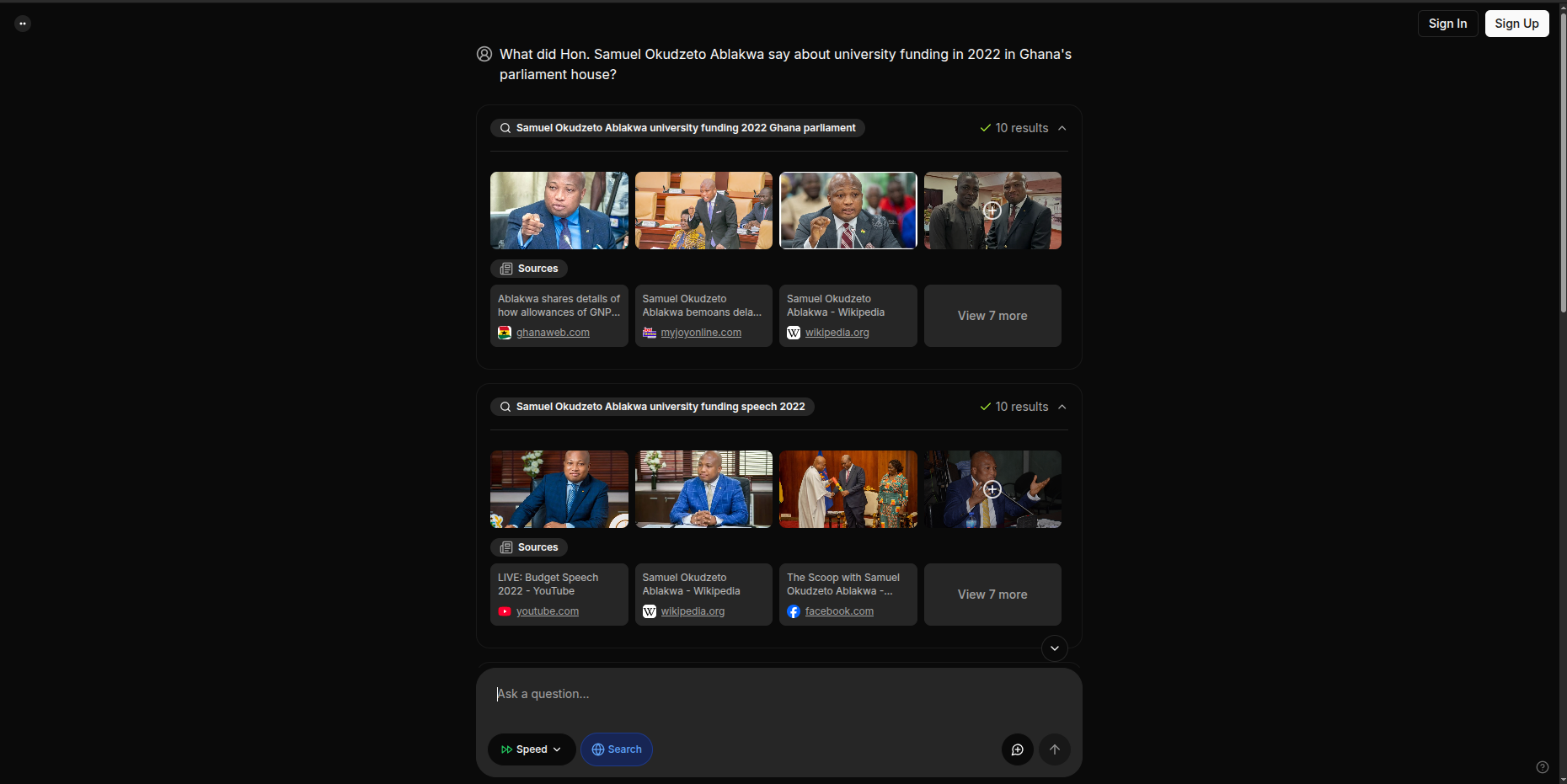
Images of chatbot responding to the question “What did Hon. Samuel Okudzeto Ablakwa say about university funding in 2022?”
Challenging the challenge
Innovative Aspects of Our Solution – Theory of Scaling Science2) Human-in-the-loop verification on high-value content
Our approach to the “Theory of Scaling Science” for this Hansard platform is to treat scalability as a sociotechnical problem — not merely a question of servers and models, but of people, trust, policy, and sustainable operations. Scaling, in this context, means ensuring that as the platform grows, it becomes more inclusive, more reliable, and more useful to citizens rather than more complex or exclusive.
Practically, we will track impact with rigorous, multi-dimensional metrics. At the technical level, we measure document-level OCR quality (word-error-rate with a target of at least 95% on high-value pages), retrieval performance (precision and recall at top-1 and top-5), and end-to-end latency (ensuring answers return in under two seconds for typical queries). At the user level, we track adoption and retention, such as repeat visits, average session duration, and completion of tasks like downloading excerpts or listening to summaries. Beyond these operational measures, we also monitor civic uptake, noting how MPs, committee staff, journalists, and civil society organizations use the platform. Importantly, we extend this to downstream policy signals — for instance, counting RTI requests triggered through the platform, or instances where Hansard insights are cited in parliamentary questions, media reports, or advocacy campaigns.
Scaling is also about fairness and inclusion. To ensure that growth does not reinforce old exclusions, we measure percent audio plays in local languages, IVR call completion rates in rural districts, and comprehension test scores across different literacy cohorts. These inclusion metrics will help confirm that citizens who are illiterate, semi-literate, or digitally underserved can still access, use, and understand parliamentary debates.
Technically, the platform is designed to scale horizontally and economically. Lightweight embeddings and vector stores like FAISS or managed services handle increasing document and query loads. At the intelligence layer, we first deploy a Retrieval-Augmented Framework (RAF) MVP to validate search, summarization, and provenance in live settings. Once high-quality labeled examples and provenance logs are collected, we move into Retrieval-Augmented Fine-Tuning (RAFT), which hardens citation fidelity and reduces hallucinations. RAFT is implemented through parameter-efficient fine-tuning (LoRA/QLoRA), allowing us to scale accuracy without scaling costs beyond reach.
Beyond the core pipeline, the platform fosters an ecosystem. We plan to expose an authenticated open API and developer sandbox so researchers, civic technologists, and journalists can build their own visualizations, cross-link Hansard with budget data or SDG indicators, and run time-series sentiment analyses. Auxiliary corpora such as budget reports, audit filings, media transcripts, and YouTube captions will be indexed in the same embedding framework, allowing seamless cross-dataset queries that show both parliamentary debate and related civic discourse.

Governance and trust are baked into this scaling strategy. Every summary is paired with a “source card” that shows the exact Hansard page or image, OCR confidence, and contributing chunks. A dispute mechanism allows flagged content to be reviewed by humans, corrected transparently, and reintroduced into the training corpus for RAFT fine-tuning. Hosting and inference costs are continuously benchmarked, with smaller local models like PHI-3 or Mistral running most day-to-day queries, while heavier models such as GPT-4 are reserved for specialized analyses. This hybrid approach makes scaling affordable without sacrificing quality where it matters.
Finally, scaling science is as much social as it is technical. Alongside the technology, we embed training programs for parliamentary staff, journalist workshops on interpreting AI outputs, and partnerships with community radio stations to reach rural users. An ethical monitoring board will oversee issues of privacy, misinformation, and bias, ensuring that the platform augments Ghana’s Right to Information framework instead of replacing formal RTI channels. Over time, this careful mix of precise metrics, incremental technical hardening, open APIs, and deliberate civic partnerships will allow the Hansard project to grow from a pilot into a resilient national infrastructure — one that transforms constitutional information rights into lived democratic practice.
The Crew
This project is being driven by a vibrant team with diverse skills. The urban planner conducts systems research and maps information needs. The cybersecurity expert leads backend and web development with security compliance. The architect crafts a clean, human-centered design and mobile UX. The ICT lead integrates NLP workflows and ensures technical cohesion. The telecom engineer optimizes for low-bandwidth users and supports system deployment.




